Информационный поиск
Содержание:
- Правильно составляйте поисковые запросы
- Альтернатива – результаты поиска в структурах
- § 4.2. Поиск информации в Интернете
- История создания ИПС
- Резюме
- 1.2 Средства WWW — WorldWideWeb (Всемирная сеть)
- Запрос и объект запроса
- Задачи информационного поиска
- Информационный поиск как наука
- Лучшая презентация результатов при группировке
- Используйте операторы поиска
- 2.3 Развитие информационного ресурса
- Задачи информационного поиска
- Виды поиска
- Правила поиска информации в Интернете
- Информационный поиск как наука
Правильно составляйте поисковые запросы
Это – самый главный и самый эффективный прием при поиске информации в интернете. Поиск по одному слову выдаст несколько миллионов результатов, поиск по двум – уже на порядок меньше, а на запрос из, скажем, четырех или шести слов – всего несколько тысяч, а то и меньше. К тому же чем точнее и грамотнее составлен запрос, тем выше вероятность, что искомый результат обнаружится на первой странице. Кроме того, не забывайте о том, что поисковые системы не всегда могут исправить орфографические ошибки в запросах, а некоторые и за ошибки не считают (например, не видят разницы между –тся и –ться, которая может оказаться принципиальной для поиска). И не игнорируйте заглавные буквы, если не хотите разбираться с лишними результатами. Скажем, запрос по слову «лебедь» выдаст результаты и с информацией о птице, и с данными о покойном генерале Александре Лебеде, а «Лебедь» – в основном о генерале, хотя будут попадаться и упоминания о птице, если слово стояло в начале предложения.
Альтернатива – результаты поиска в структурах
Механизмы, использующие кластерный анализ (data clustering, кластеризация) обеспечивают лучшую презентацию результатов поиска, потому что организуют их в структуру. Этот метод заключается в назначении определенных категорий или тематик документам и результатам поиска.
Понятие кластер означает множество, совокупность, связку или просто группу. Кластеризация направлена на – насколько это возможно – сортировку результатов поиска в одну или несколько таких групп, и таким образом извлекает группы из всех результатов.
Условием успеха является предварительное определение групп, а также категорий, тематик или слоев, которые, в свою очередь, определяются ключевыми словами и профессиональными понятиями. Для того, чтобы документ мог быть назначен группе, он должен быть правильно классифицирован.
Реализация этого намерения не всегда оказывается достаточно простой. Чтобы ее сделать, поисковая система читает, после чего исследует данные и метаданные документа
Также анализирует содержание документа на основе статистических расчетов (принимает во внимание частоту появления букв, слогов и слов, порядок фраз, а также длины слов и предложений), или использует алгоритмы лингвистического анализа. Чем более точны эти данные, тем точнее можно выделить документ в определенной группе
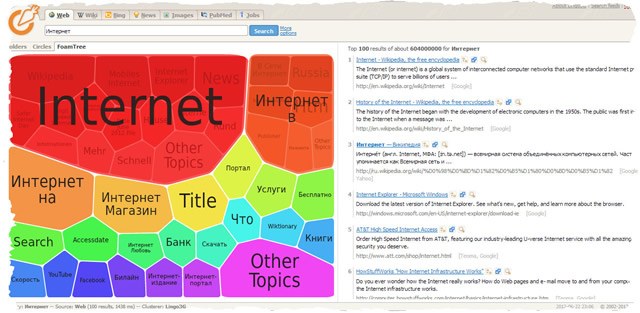
«Морковный» поиск с новаторским способом визуализации результатов в виде мыльных пузырей в пене, которые разграничивают отдельные тематические группы. Умышленная «ошибка» в запросе, показывает, что инструмент самостоятельно исправляет ошибки.
§ 4.2. Поиск информации в Интернете
Содержание урока
4.2. Поиск информации в Интернете
4.2. Поиск информации в Интернете
Сеть Интернет растет очень быстрыми темпами, поэтому найти нужную информацию становится все сложнее. Для поиска информации используются специальные поисковые системы, которые содержат постоянно обновляемую информацию о местонахождении Web-страниц и файлов на серверах Интернета.
Поисковые системы содержат тематически сгруппированную информацию об информационных ресурсах Всемирной паутины в базах данных. Специальные программы-роботы периодически «обходят» Web-серверы Интернета, читают все встречающиеся документы, выделяют в них ключевые слова и заносят в базу данных Интернет-адреса документов.
Большинство поисковых систем разрешают автору Web-сайта самому внести информацию в базу данных, заполнив регистрационную анкету. В процессе заполнения анкеты разработчик сайта вносит адрес сайта, его название, краткое описание содержания сайта, а также ключевые слова, по которым легче всего будет найти сайт.
Поиск по ключевым словам. Поиск документа в базе данных поисковой системы осуществляется с помощью введения запросов в поле поиска.
Запрос должен содержать одно или несколько ключевых слов, которые являются главными для этого документа. Например, для поиска самих систем поиска в Интернете можно в поле поиска ввести ключевые слова «российская система поиска информации Интернет».
Через некоторое время после отправки запроса поисковая система вернет список ссылок на документы, в которых были найдены указанные ключевые слова. Для просмотра такого документа в браузере достаточно активизировать указывающую на него ссылку.
Если ключевые слова были выбраны неудачно, то список ссылок на документы может быть слишком большим (содержать десятки и даже сотни тысяч ссылок). Для того чтобы уменьшить список, можно в поле поиска ввести дополнительные ключевые слова или воспользоваться каталогом поисковой системы.
Одной из наиболее полных и мощных поисковых систем является (www.google.ru), в базе данных которой хранятся более 300 миллиардов Web-страниц, и каждый месяц программы-роботы заносят в нее 5 миллионов новых страниц (рис. 4.9). В российской части Интернета обширные базы данных, содержащие по 400 миллионов документов, имеют поисковые системы Яндекс (www.yandex.ru), Mail (www.mail.ru) и Rambler (www.rambler.ru).
Поиск в иерархической системе каталогов. В базе данных поисковой системы Web-сайты группируются в иерархические тематические каталоги, которые являются аналогами тематического каталога в библиотеке.
Тематические разделы верхнего уровня, например «Интернет», «Компьютеры», «Наука и образование» и т. д., содержат вложенные каталоги. Например, каталог «Интернет» может содержать подкаталоги «Поиск», «Сервис» и др.
Рис. 4.9. Поиск по ключевым словам в системе Google
Поиск информации в каталоге сводится к выбору определенного каталога, после чего пользователю будет представлен список ссылок на наиболее посещаемые и содержательные Web-сайты. Каждая ссылка обычно аннотирована, т. е. содержит короткий комментарий к содержанию документа.
Наиболее полный многоуровневый иерархический тематический каталог русскоязычных Интернет-ресурсов имеет поисковая система Апорт (www.aport.ru) (рис. 4.10). Каталог содержит подробную аннотацию содержания Web-сайтов и указание на их географическое положение.
Поиск файлов. Для поиска файлов на серверах файловых архивов существуют специализированные поисковые системы, в том числе российская файловая поисковая система FileSearch (www. filesearch.ru). Для поиска файла необходимо имя файла ввести в поле поиска, и поисковая система выдаст ссылки на серверы файловых архивов, на которых хранится файл с заданным именем.
Рис. 4.10. Тематические каталоги поисковой системы Апорт
Cкачать материалы урока
История создания ИПС
Самые первые ИПС появились в середине 90 – х годов 20 века. Они весьма напоминали обычные указатели, которые находятся в любых книгах, некие справочники. В их базе данных содержались специальные ключевики (слова), которые различными способами собирались с многочисленных сайтов. Так, как интернет – технологии были не совершенными, то и сам поиск выполнялся только по ключевым словам.
Значительно позднее был разработан специальный полнотекстовый поиск, облегчающий нахождение необходимой пользователю информации. Система производила фиксацию ключевых слов. Благодаря ей, пользователи могли производить нужные запросы по тем или иным словам и различным словосочетаниям.

Одной из первых, была «Wandex». Ее разработкой занимался очень известный программист Мэтью Греэм в 1993 году. Также, в этом же году возникла и новая «поисковка» «Aliweb» (кстати, и по сей день успешно работает). Однако все они имели достаточно сложную структуру и не обладали современными технологиями.
Одной из наиболее удачных явилась «WebCrawler», которая впервые была запущена в 1994 году. Отличительной особенностью и главным преимуществом, выгодно выделяющим ее среди других систем поиска, явилось то, что она могла находить любые ключевики на той или иной странице. После этого, это стало своего рода эталоном и для всех остальным ИПС, которые разрабатывались позднее.
Значительно позже возникли и другие поисковики, которые иногда конкурировали между собой. Это были – «Excite», «AltaVista», «InfoSeek», «Inktomi» и многие другие. Начиная с 96 года, российские пользователи сети начали работать с «Рамблером» и «Апортом». Но, настоящим триумфом для российского интернета, стал созданный в 1997 году «Яндекс».
Этот российский аналог «Google» стал настоящей гордостью российских программистов. Сегодня, он уверенно теснит конкурента в рунете и также является одним из лидеров по поисковым запросам среди ИПС в России.
На сегодняшний день, имеются многочисленные специальные «поисковики», которые созданы для решения определенных задач. Так, например, информационно – поисковая система «Патрон», разработана для того, чтобы хранить и искать данные по патронам для различного оружия и сейчас применяется, как в органах Министерства Внутренних Дел и спецслужб, так и для охотников – профессионалов и любителей.
Имеются и другие, разработанные для нотариусов, врачей, инженеров, военных, автолюбителей и т д
Резюме
Мы разобрали, как правильно искать в Интернете быстро и просто. Вы узнали, каким источникам в сети можно доверять, а какую информацию стоит перепроверять. Изучили примеры поиска в зависимости от поставленной задачи.
Рекомендуем
 Что такое Title, мета теги, заголовок H1 и как их правильно написать?
Что такое Title, мета теги, заголовок H1 и как их правильно написать?
Когда вы пишете тексты для сайтов, вебмастера просят вас добавить в Title, мета-теги и заголовок H1 определенные слова. Давайте разберемся, что …
 Способы заработка на текстах в Интернете: как и сколько можно заработать?
Способы заработка на текстах в Интернете: как и сколько можно заработать?
В этой статье я расскажу, как и сколько можно зарабатывать написанием текстов в Интернете, где искать заказы и как быстро выйти на хороший доход. …
1.2 Средства WWW — WorldWideWeb (Всемирная сеть)
В 1993 году была разработана информационно-поисковая система WWW, которая благодаря простоте навигации и доступности открыла информационные источники Интернета неподготовленным пользователям. WWW вызвал бум в сети Интернет, который продолжается по настоящее время, и объемы доступной информации Интернета ежегодно удваиваются.
WWW основывается на принципе гипертекста (уже знакомого читателю), то есть на системе документов, связанных гиперссылками. Гипертекст представляет собой ключевые Слова, особым образом выделенные из обычного текста. Гипертекстовые ссылки отправляют пользователя на другие документы того же сервера либо на другие сервера, которые могут располагаться в любом месте Интернета. Если этот текстовый документ тоже гипертекстовый, то его ссылки позволяют перейти далее на соответствующие документы. Каждая переадресация происходит для пользователя незаметно, так что он может просматривать информационный состав Интернета но содержательному принципу, не заботясь об адресации конкретных компьютеров.
С развитием мультимедийных приложений изначально чисто гипертекстовые документы все больше и больше становятся гипермедийными. Таким образом, WWW-документы могут существовать в любом формате данных: текст, графика, звук/музыка или видеоклип. Ориентация и навигация во Всемирной сети происходят с использованием специальных программ, называемых WWW-браузерами, обеспечивающими пользовательский интерфейс, как, например, NetscapeNavigator или MicrosoftInternetExplorer.
Отправной точкой поиска информации служит, как правило, основная (базовая, домашняя) страница (сайт) информационного ресурса, которой можно достичь, введя соответствующий адрес в браузере (например, http://ncpi.gov.byили www.iparegistr.com). WWW-сайты создаются и обновляются фирмами либо специальными организациями, публикующими информацию и следящими за содержанием своих WWW-страниц. Использование WWW, таким образом, не является пассивным, и каждый пользователь Интернета при помощи специальных программ-редакторов гипертекста может самостоятельно создавать собственные интерактивные WWW-страницы. Это и открыло путь для растущей коммерциализации и расширения Интернета.
С появлением WWW-службы и начался бум в сети Интернет. Благодаря этой простой в применении и единой для всех служб пользовательской среде Интернет заинтересовал множество людей и организаций. Оказалось вдруг, что не надо быть специалистом в области Интернета, чтобы пользоваться службами сети. Это можно сравнить с успехом фирмы Microsoft, связанным с выпуском MicrosoftWindows в качестве графической пользовательской оболочки. До появления Windows у каждого DOS-приложения было собственное руководство пользователя и тем самым требовалось отдельно изучать каждое приложение.
Запрос и объект запроса
Говоря о системах ИП, употребляют термины запрос и объект запроса.
Запрос — это формализованный способ выражения информационных потребностей пользователем системы. Для выражения информационной потребности используется язык поисковых запросов, синтаксис варьируется от системы к системе. Кроме специального языка запросов, современные поисковые системы позволяют вводить запрос на естественном языке.
Объект запроса — это информационная сущность, которая хранится в базе автоматизированной системы поиска. Несмотря на то, что наиболее распространенным объектом запроса является текстовый документ, не существует никаких принципиальных ограничений. В частности, возможен поиск изображений, музыки и другой мультимедиа информации. Процесс занесения объектов поиска в ИПС называется индексацией. Далеко не всегда ИПС хранит точную копию объекта, нередко вместо неё хранится суррогат.
Задачи информационного поиска
Центральная задача ИП — помочь пользователю удовлетворить его информационную потребность. Так как описать информационные потребности пользователя технически непросто, они формулируются как некоторый запрос, представляющий из себя набор ключевых слов, характеризующий то, что ищет пользователь.
Классическая задача ИП, с которой началось развитие этой области, — это поиск документов, удовлетворяющих запросу, в рамках некоторой статической коллекции документов. Но список задач ИП постоянно расширяется и теперь включает:
- Вопросы моделирования;
- Классификация документов;
- Фильтрация документов;
- Кластеризация документов;
- Проектирование архитектур поисковых систем и пользовательских интерфейсов;
- Извлечение информации, в частности аннотирования и реферирования документов;
- Языки запросов и др.
Также, перед движками ИП ставятся некоторые задачи по обработке естественных языков, что включает в себя морфологический анализ, разрешение лексической многозначности и так далее.
Информационный поиск как наука
Информационный поиск — большая междисциплинарная область науки, стоящая на пересечении когнитивной психологии, информатики, информационного дизайна, лингвистики, семиотики, и библиотечного дела.
Поиск информации — процесс выявления в массиве информации записей, удовлетворяющих заранее определенному условию поиска или запросу.
ИП рассматривает поиск информации в документах, поиск самих документов, извлечение метаданных из документов, поиск текста, изображений, видео и звука в локальных реляционных базах данных, в гипертекстовых базах данных таких, как Интернет и локальные интранет-системы.
Существует некоторая путаница, связанная с понятиями поиска данных, поиска документов, информационного поиска и текстового поиска. Тем не менее, каждое из этих направлений исследования обладает собственными методиками, практическими наработками и литературой.
В настоящее время ИП — это бурно развивающаяся область науки, популярность которой обусловлена экспоненциальным ростом объемов информации, в частности в сети Интернет. ИП посвящена обширная литература и множество конференций. Одной из наиболее известных является TREC, организованной в 1992 Министерством обороны США совместно с Институтом Стандартов и Технологий (NIST) с целью консолидации исследовательского сообщества и развития методик оценки качества ИП.
Лучшая презентация результатов при группировке
Напрашивается вопрос, что дает пользователю объединение результатов в группе. С технической точки зрения, позволяет почти в любой форме представлять результаты поиска.
Упомянутый мыльный пузырь по одной теме может быть разделен на более мелкие сегменты. Описанный способ визуализации может раскрывать для пользователя дополнительную информацию. Если вы не знаете, например, что композитор Фредерик Шопен тесно связан со столицей Франции, Парижем, без труда заметите этого отношения в «пенке», представляющей результаты поиска.
Когда вы нажмете один из мыльных пузырей в пределах пены, в правой части окна появится список документов, тематически связанных с размещенным в нем понятием более высокого уровня. Рядом с заголовком страницы видны три маленьких значка. Нажатие первого вызывает результаты поиска в пределах групп.
Вторая икона позволяет открыть новую вкладку в браузере и просмотреть в ней содержание страницы, на которую ведет ссылка. Третий – обеспечивает предварительный просмотр результата поиска (и, следовательно, содержания целевой страницы).
Под каждым заголовком страницы появляется небольшой фрагмент текста с целевой страницы. Найденные на нем запросы пользователя, будут выделены жирным шрифтом (аналогичное решение используется в поиске Google). URL целевой страницы указан под фрагментом текста.
Рядом с ним перечень, в квадратных скобках, поисковых систем, которые нашли данную ссылку и сайт. Когда вы указываете определенную категорию в разделе результаты поиска, вы получите ссылку для дальнейшего изучения по сходству и возможность сузить тематику.
Если визуализация в виде пены (FoamTree) не помогла Вам найти ответ, вы можете использовать два других способа графического представления результатов: категории и круговая диаграмма.
Способ обработки круговой визуализации требует некоторых объяснений
- Когда вы поместите курсор мыши над частью круговой диаграммы, инструмент Carrot Search выделит черным цветом все точки, относящиеся к выбранному вами сегменту;
- Когда вы нажимаете на определенный сектор окружности, инструмент Carrot Search ограничивает список выведенный с правой стороны на этих результатах поиска, которые связаны с выбранным вами сегментом;
- Когда нажмете на черную точку, или результат поиска в правой панели, инструмент Carrot Search откроет целевую страницу, которая содержит требуемый результат.
Поисковая система Carrot Search – англоязычный проект. Работа с ней требует оплаты, однако, вы можете попробовать ее возможности, с помощью демо-версии.
Используйте операторы поиска
Этот совет не случайно стоит последним: он годится скорее продвинутым пользователям и тем, кто в школе хорошо успевал по точным наукам. Поэтому мы даже не будем углубляться в подробное описание всех операторов поиска. Скажем только, что операторы поиска – это специальные знаки типа «+», «-», «~», «|» и так далее, подставляемые в текст запроса. Их использование позволяет включать и исключать из поиска конкретные слова из словосочетания, добиваться, чтобы поисковая машина искала словосочетание в пределах одного предложения или одного документа и так далее. А если читателю интересно побольше об этом узнать – он может ввести в поисковую строку словосочетание «операторы поиска», а потом воспользоваться всеми вышеприведенными советами. Результат гарантирован!
2.3 Развитие информационного ресурса
Как и другие информационные технологии, Интернет создают разработчики, но в данном случае в основном это создатели ресурсов (начиная от специалистов, ведущих поддержку hard- и software, дизайнеры, художники, редакторы и самое главное — авторы информационных ресурсов). Естественно, создание ресурсов — не самоцель, ресурсы востребуются пользователями сети, то есть теми же специалистами и потребителями ресурсов, среди которых, как уже отмечалось, появляется новый слой — специалисты по datamining, по поиску информации. Информационные ресурсы Интернета, как, впрочем, и другие, в том числе неэлектронные информационные ресурсы (в частности, средства массовой информации), характеризуются определенными состояниями своей деятельности (рис. 9.3).
Ресурс зарождается в соответствии с потребностями общества и его возможностями (в частности, связанными с уровнем технического и социального состояния общества).
По мере возможности происходит «взросление», становление ресурса (или его исчезновение при полном отсутствии востребованности, то есть исчезновение, возможно, не в физическом смысле — сайт может существовать, а именно в смысле востребованности).
При определенном уровне востребованнности и (в том числе и стараниями авторов сайта) происходит его каталогизация, то есть сведения о ресурсе появляются в различных каталогах, соответствующих типу ресурса.
Индексирование, то есть появление ресурса в индексах поисковых машин, происходит при достижении определенных объемов информационного наполнения и востребованности.
При наличии постоянного роста востребованности происходит и постоянное развитие ресурса, в противном случае ресурс угасает и постепенно исчезает из индексов и каталогов.
Задачи информационного поиска
Центральная задача ИП — помочь пользователю удовлетворить его информационную потребность. Так как описать информационные потребности пользователя технически непросто, они формулируются как некоторый запрос, представляющий из себя набор ключевых слов, характеризующий то, что ищет пользователь.
Классическая задача ИП, с которой началось развитие этой области, — это поиск документов, удовлетворяющих запросу, в рамках некоторой статической коллекции документов. Но список задач ИП постоянно расширяется и теперь включает:
- Вопросы моделирования;
- Классификация документов;
- Фильтрация документов;
- Кластеризация документов;
- Проектирование архитектур поисковых систем и пользовательских интерфейсов;
- Извлечение информации, в частности аннотирования и реферирования документов;
- Языки запросов и др.
Также, перед движками ИП ставятся некоторые задачи по обработке естественных языков, что включает в себя морфологический анализ, разрешение лексической многозначности и так далее.
Виды поиска
Полнотекстовый поиск — поиск по всему содержимому документа. Пример полнотекстового поиска — любой интернет-поисковик, например www.yandex.ru, www.google.com. Как правило, полнотекстовый поиск для ускорения поиска использует предварительно построенные индексы. Наиболее распространенной технологией для индексов полнотекстового поиска являются инвертированные индексы.
Поиск по метаданным — это поиск по неким атрибутам документа, поддерживаемым системой — название документа, дата создания, размер, автор и т. д. Пример поиска по реквизитам — диалог поиска в файловой системе (например, MS Windows).
Правила поиска информации в Интернете
1. Сформулируйте несколько запросов по вашему вопросу. Учитывайте при этом, что если вам надо найти реферат о слоне, то по слову слон вы найдете слонов и всего того, что может и не может относиться к слову слон. Это могут быть книги со словом слон в заголовке, это могут быть сайты, статьи, анекдоты, сказки, вообщем, все то, что к вашему настоящему запросу не имеет никакого отношения. Поэтому пишем коротко и ясно: рефераты о слонах. Для увеличения нажмите на картинку.
Яндекс нам выдал 2 млн ответов, Гугл оценил, что нам будут полезны 335000 страниц. Как видите, придется попотеть, чтобы найти то, что нам действительно нужно.
2. Сузим область поиска. Для этого заключим в кавычки наш запрос, и он будет выглядеть так: “рефераты о слонах”. Посмотрим, что получится:
О чудо! Искать придется теперь гораздо меньше! Теперь мы уверены, что на этих страницах, которые нам предоставили поисковики, будет информация, связанная с рефератами о слонах.
3. Не забываем о том, что писать поисковый запрос нужно грамотно. От этого также зависит качество выданной нам информации.
4. Поисковый запрос пишем только маленьким буквами. Если мы используем в запросе большие буквы, то не сможем увидеть ответы, где данное слово пишется с маленькой буквы. Используйте заглавные буквы только в именах собственных.
5. Активно используем поиск в картинках. Обычно, картинки имеют подписи при загрузке, в которых могут прописаны именно ваши ключевые слова.
6. С помощью знаков + и – можно указать какие слова мы хотим или не хотим видеть. Например, при запросе “зеленый чай” можно отметить знаком (-) слово пакетированный. В этом случае, можете рассчитывать на то, что информацию о зеленом чае в пакетиках вы не увидите.
7. Знак | сможет дать понять поисковым системам, что вы хотите найти “или-или”. Если вы спросите “как написать реферат|оформить реферат”, то в ответах у вас будут и как написать реферат и как его оформить.
8. Знаком ! мы указываем, что хотим знать точную информацию по конкретному слову. Например, при поиске запроса !слон, мы увидим точное соответствие данному слову без словоформ. То есть, в поиске не будут отображены различные формы слова “слон” – слоны, слонов, слонами, о слонах и т.д.
9
Принимайте во внимание, что через какое-то время поиск может выдать вам совершенно другую информацию. Поэтому найденную информацию, если она вам действительно важна, лучше всего сохранять в избранном или в закладках браузера
Используйте систему хранения информации в своем браузере с помощью папок, их можно создавать прямо на панели, нажав правой кнопкой мыши и выбрав “добавить папку”. Я предпочитаю сохранять с метками в Evernote, можете прочитать о моем любимом помощнике в статье “Супер-человек? С Evernote возможно!”
10. Используйте функции расширенного поиска поисковых систем, если вам нужны уточнения по датам, географии, языку, формату файла.
11. Не пренебрегайте поиском на 2-й и последующих страницах. Часто бывает, что свежая и новая информация еще не успела попасть в ТОП 10, поэтому ее придется поискать. Иногда я нахожу свои сайты на пятой, или даже десятой странице.
12. Если вам постоянно нужна информация по конкретной сфере деятельности, используйте для сбора информации социальные сети, сообщества, группы, форумы, каталоги. Рассылка сервиса Subscribe может предложить вам большое количество специализированных, тематических групп, которые будут постоянно присылать на вашу почту новую информацию. Самое нужное и интересное вы также можете сохранять в закладках браузер или в любом удобном для этого дела сервисе, например, Evernote.
Информационный поиск как наука
Информационный поиск — большая междисциплинарная область науки, стоящая на пересечении когнитивной психологии, информатики, информационного дизайна, лингвистики, семиотики, и библиотечного дела.
Поиск информации — процесс выявления в массиве информации записей, удовлетворяющих заранее определенному условию поиска или запросу.
ИП рассматривает поиск информации в документах, поиск самих документов, извлечение метаданных из документов, поиск текста, изображений, видео и звука в локальных реляционных базах данных, в гипертекстовых базах данных таких, как Интернет и локальные интранет-системы.
Существует некоторая путаница, связанная с понятиями поиска данных, поиска документов, информационного поиска и текстового поиска. Тем не менее, каждое из этих направлений исследования обладает собственными методиками, практическими наработками и литературой.
В настоящее время ИП — это бурно развивающаяся область науки, популярность которой обусловлена экспоненциальным ростом объемов информации, в частности в сети Интернет. ИП посвящена обширная литература и множество конференций. Одной из наиболее известных является TREC, организованной в 1992 Министерством обороны США совместно с Институтом Стандартов и Технологий (NIST) с целью консолидации исследовательского сообщества и развития методик оценки качества ИП.